
淺談 Solr 檢索的 相關度排名 (Ranked Retrieval)

Solr 搜尋引擎最重要的工作,在於:找出並呈現對使用者有用的資訊。
在 關聯性資料庫的環境中,一筆資料只有「符合」或「不符合」SQL query 篩選出的結果,只是其結果準確度描述,則付之闕如。
但在 Solr 檢索引擎,則是完全不同概念: Solr 根據「相關性」的「分數」比重,決定何者排 前->後。
是否有種熟悉的感覺? 這很像我們操作 google ,找出最適合我們的網站檢索結果。
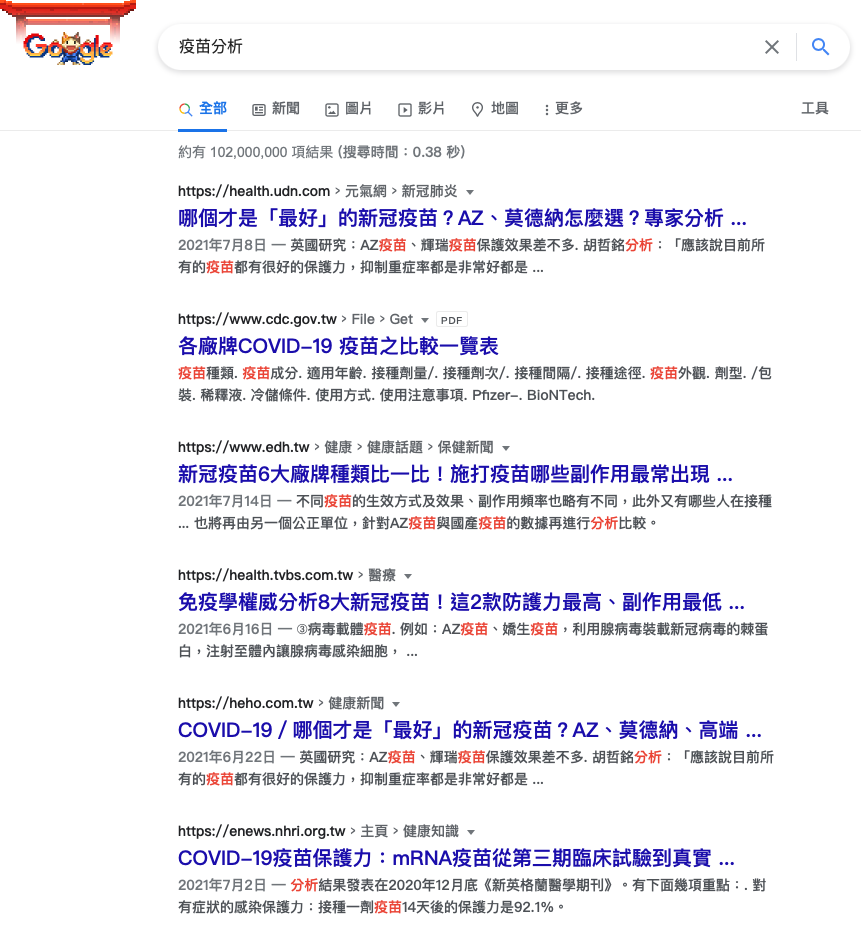
為何檢索的相關度排序如此重要?
- 現代搜尋引擎處理的資料量是億萬等級累積計算,如果沒有「相關度排名」提供參考,使用者將迷失在浩瀚無垠的資料地獄之中。
- 現代使用者已習慣搜尋引擎帶來的簡便性,如果使用者輸入關鍵字後,還需注意自己是否打錯字或是還要考慮同音、同義字,相信使用者一定極度不耐煩。簡單來說,使用者期待 Solr 不僅要「照我輸入的關鍵字查找」,他也期待 Solr 能「理解我要找的東西」
當然,Solr 要能符合上述運作的流暢度,適度的調教「相關度排名」因子,將非常重要。
如何進行?你可以選擇下列方式:
- 選擇某些特定欄位加強其相關度權重
- 預先定義好同義詞表/冗余詞
- 給予較新的文件較高權重
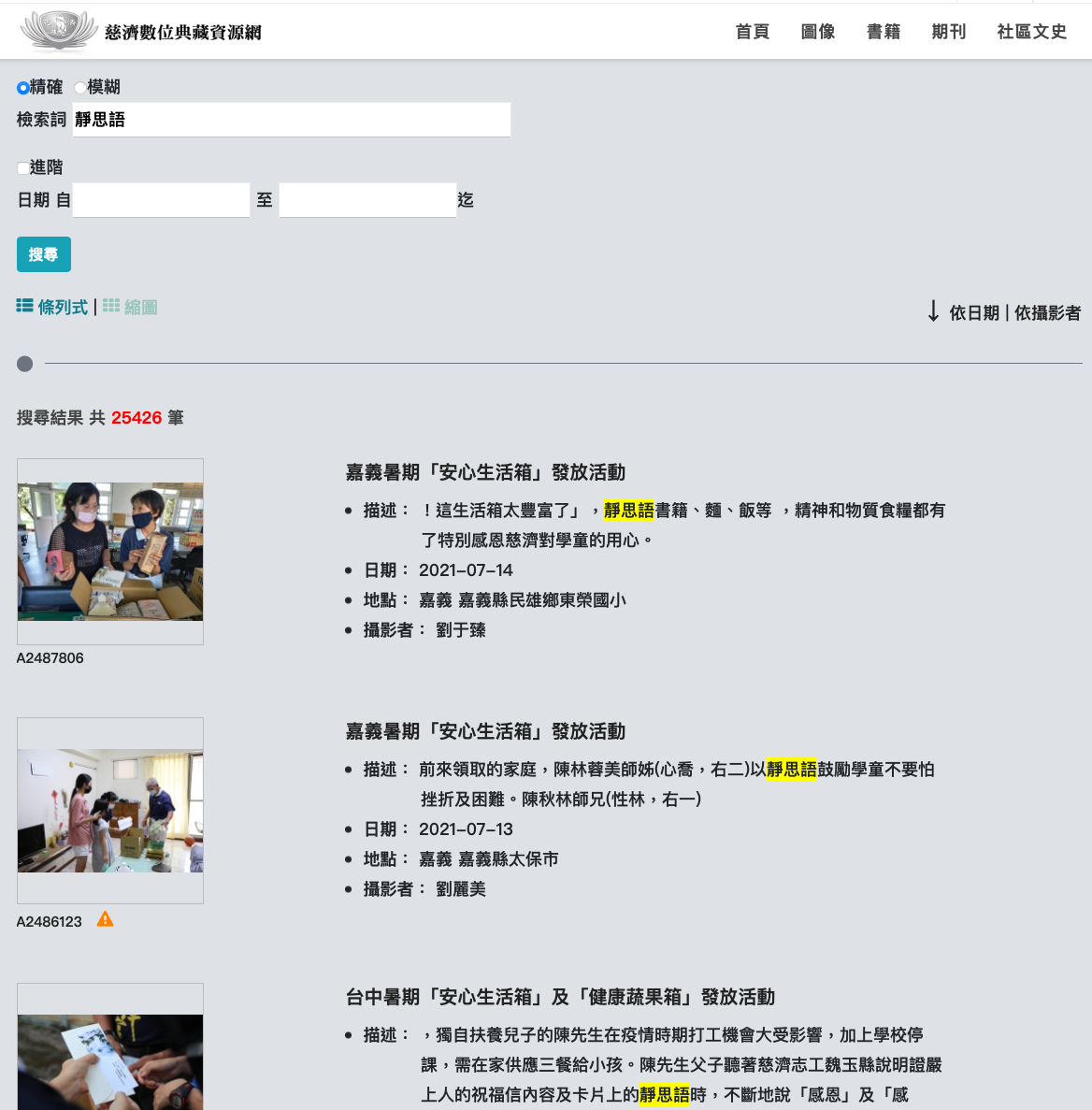
(慈濟- 數位典藏資源網: 統整全球慈濟數位文物,使用 Solr 供志工、民眾搜尋、瀏覽。該網站由 詩農創意科技 建置)
當然,以上只是舉例。就像檢索引擎業者,微軟、google、DuckDuckGo 都有其獨門之處,你也運用創意可以打造出專屬於自己網站、產品或服務的檢索服務。