Bootstrap 簡介: 前端開發者的福音
Bootstrap 是一個由 HTML、CSS 和 JavaScript 寫成的框架。 它快速方便解決前端開發者,在進行 RWD 自適應 網頁時,需面臨切換不同語言繁雜作業。 簡單來說:bootstrap 可以敏捷快速的完成網站前端建置。 Bootstrap 包含了 基本的模組- Grid、Typography、Tables、Forms、Buttons 和Responsiveness 前端組合包-
詳情...網站建置 系統開發 的專家


Bootstrap 是一個由 HTML、CSS 和 JavaScript 寫成的框架。 它快速方便解決前端開發者,在進行 RWD 自適應 網頁時,需面臨切換不同語言繁雜作業。 簡單來說:bootstrap 可以敏捷快速的完成網站前端建置。 Bootstrap 包含了 基本的模組- Grid、Typography、Tables、Forms、Buttons 和Responsiveness 前端組合包-
詳情...
Solr 搜尋引擎最重要的工作,在於:找出並呈現對使用者有用的資訊。 在 關聯性資料庫的環境中,一筆資料只有「符合」或「不符合」SQL query 篩選出的結果,只是其結果準確度描述,則付之闕如。 但在 Solr 檢索引擎,則是完全不同概念: Solr 根據「相關性」的「分數」比重,決定何者排 前->後。 是否有種熟悉的感覺? 這很像我們操作 google ,找出最適合我們的網站檢索結果。
詳情...
Solr 內部核心為 Lucene 檢索引擎,對外則是一 Web application(網路應用程式)介面。 因 Solr 使用開放式 web 協定,所以它支援眾多的客端程式語言與其連接溝通。 最讓人振奮的:HTTP 其實就是 Solr 對外溝通的核心協定,即時你不使用專屬程式包 API 與 Solr 連動,你依然可使用最基礎的 web url 指令來操作 Solr。 舉例來說:如果我要取一筆編
詳情...
我們都知道 Solr 技術底層使用了 Lucene 技術,而 Lucene 檢索核心就是 反向索引(Inverted Index)。 什麼是 反向索引 ?它與平時資料庫檢索概念有什麼不同? 傳統資料庫 database 節錄資料方式,是給予每份文件一個獨一無二 (unique)的 ID編號。 然後在此 ID 編號,紀錄下這筆ID文件的各個欄位值(例如:一筆學生資料ID編號35,其可能儲存了姓名、身
詳情...
不少開發人員遇見 solr 的第一個問題,總是: “到底 Solr 與 SQL RDBMS 有啥不同? 孰優孰劣?” 其實 Solr 與 關聯式資料庫 RDBMS們(例如 MySQL、SQL、Oracle) ,這兩類並非競爭關係。 相反的,其實它們是為了成就更完整的彼此而存在。 簡單來說,RDBMS 遵循 ACID 原則(Atomicity 原子性、Consistency 一致性、Isolatio
詳情...什麼是 solr? solr 是目前最廣泛使用的企業級搜尋引擎。 solr 不僅可進行全文檢索,他還能作為文件儲存型的 NoSQL 資料庫型態,支援交易紀錄,也能儲存 key-value 的資料型態。非常強大、效率。 solr 的技術架構由 RESTful XML/HTTP 以及 JSON APIs組成,支援目前世界廣泛使用的程式語言,例如:JAVA、Phyton、Ruby、C#、PHP 等。 最
詳情...
許多網站系統專案,常會使用到 Google Calendar 行事曆整合。 例如,行程發佈或是報名後,要同步到使用者自己的 Google Calendar 行事曆。 網站系統如要與 Google calendar 行事曆,有幾個前置動作 先至 Google API Console 進行申請動作。 利用申請後, googele 核發的 credential 與 clientID ,作為鑰匙。 以後就
詳情...
最近開發專案,遇到這個惱人小問題: 每每修改 CSS code 或 javascript 檔案,網頁一刷新,還是不動如山啊! 😡 實驗後,原來是遇到 CACHE 快取問題,這部分與使用者瀏覽器有關:
詳情...
第一次開發 WordPress PLUGIN時,縱然讀完 WordPress 官網開發指南後, 往往不知從何開始建立程式,一頭霧水。 幸運的是,DevinVinson 為大家預先製作了一套 PLUGIN 樣板 – 「Boilerplate」
詳情...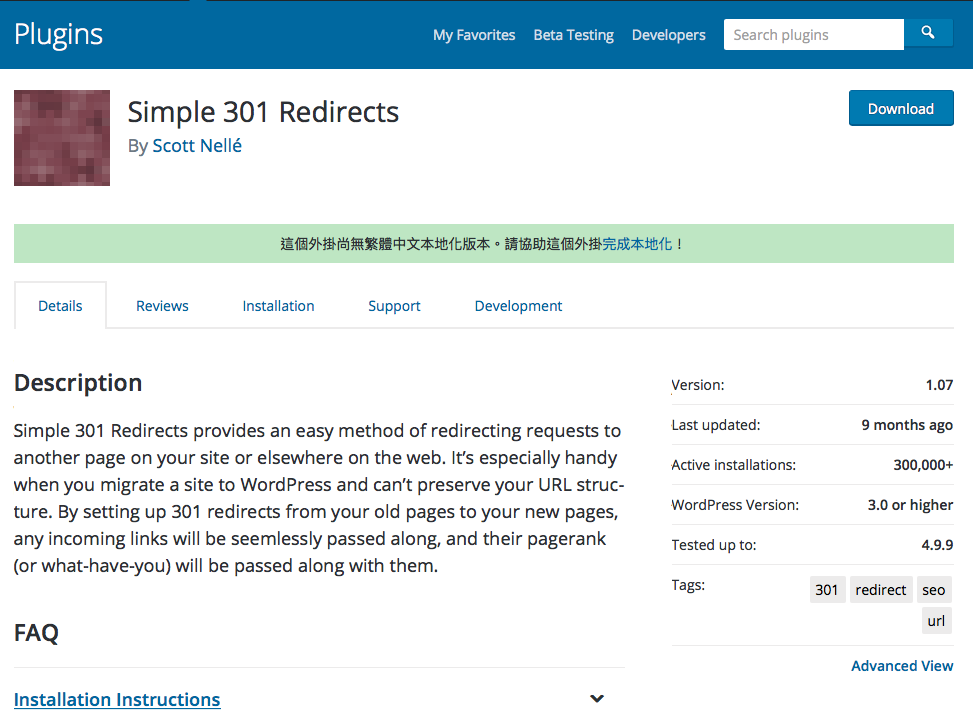
許多網站,近期面臨 google 對於網址 https 的加密要求,紛紛進行改版工程。 這些改版工程都面臨一個重要議題: 改版工程中,過去累積的 SEO 頁面排名成績怎麼辦? 例如:網址由 http://aaaa.com/b.html => https://aaa.com/b.html 時, 對於搜尋引擎來說,這兩者是不一樣的網頁, 因此,過去累積的 pagerank 分數,無法直接繼承。
詳情...